Open Expert Survey 2021 (OES21)
Die verschiedenen Datensätze
Der OES21 stellt folgenden Datensätze zur Verfügung:
“oes21_raw_expert_positions”
Dieser Datensatz enthält die Rohdaten der Expert:innen-Einschätzungen. Jede Zeile ist ein:e Expert:in und in den Spalten sind die Positionen der Parteien (bspw. Links-Rechts-Positionierung der CDU) oder weitere Informationen zu den Expert:innen (bspw. Statusgruppe, Teilbereich). Alle anderen Datensätze wurden auf Basis dieser Ausgangsdaten erstellt.
“oes21_positions_tidy”
Dieser Datensatz enthält die aggregierten Positionen der Parteien anhand des Medians und des Mittelwerts im “tidy”-Format. D.h. jede Zeile ist die Kombination aus dem jeweiligen Item (bspw. Links-Rechts-Position, Position zu Einwanderung, etc.) und Partei (bspw. CDU, CSU, SPD, …). Der Datensatz enthält auch die Anzahl an Beobachtungen, die für die Aggregation genutzt wurden und die Anzahl an fehlenden Werten. Weiterhin werden min.- und max.-Werte sowie die Standardabweichung ausgegeben.
Zusätzlich enthält der Datensatz auch die Werte aus dem Expert Survey 2017 und aus der Expertenbefragung von Benoit und Laver (2006). Somit liefert dieser Datensatz eine Zeitreihe.
“oes21_medians_wide”
Dieser Datensatz für jede Partei eine Zeile und in den Spalten sind die Positionen zu den jeweiligen Politikdimensionen basierend auf dem Median der Expert:innen-Einschätzungen.
“oes21_means_wide”
Dieser Datensatz für jede Partei eine Zeile und in den Spalten sind die Positionen zu den jeweiligen Politikdimensionen basierend auf dem Mittelwert der Expert:innen-Einschätzungen.
Codebücher
Alle Variablennamen, Fragetexte, Skalen und eine Zusammenfassung der Positionen anhand gängiger deskriptiver Statistiken findet sich in dem Codebook (oes21_codebook.pdf).
Eine umfassende Tabelle aller Positionen, basierend auf der positions_tidy Datei, findet sich unter oes21_tabellarisch.pdf.
Beispiele für Nutzung
raw_expert_positions
Der Datensatz eignet sich besonders für eigene Aggregationsanalysen oder wenn der Einfluss von Expert:innen-Eigenschaften analysiert werden sollen.
# Einlesen der Daten
raw_experts <- readRDS("oes21_raw_expert_positions.rds")
# Bsp. Analyse: Ökon. Links-Rechts-Positionierung der Parteien anhand von Statusgruppe
raw_experts %>%
select(academictitle, matches("leftrightecon_[a-z]+$")) %>%
pivot_longer(cols = starts_with("leftrightecon_"),
names_to = "Party",
values_to = "Positions") %>%
group_by(academictitle, Party) %>%
summarise(Positions = median(Positions, na.rm = TRUE)) %>%
ggplot(aes(x = Party,
y = Positions,
fill = academictitle,
color = academictitle)) +
geom_point(position = position_dodge(width = 0.9)) +
theme_bw() +
coord_flip() +
xlab("") +
ylab("Ökonom. Links-Rechts (Median)") +
theme(legend.position = "bottom")## `summarise()` regrouping output by 'academictitle' (override with `.groups` argument)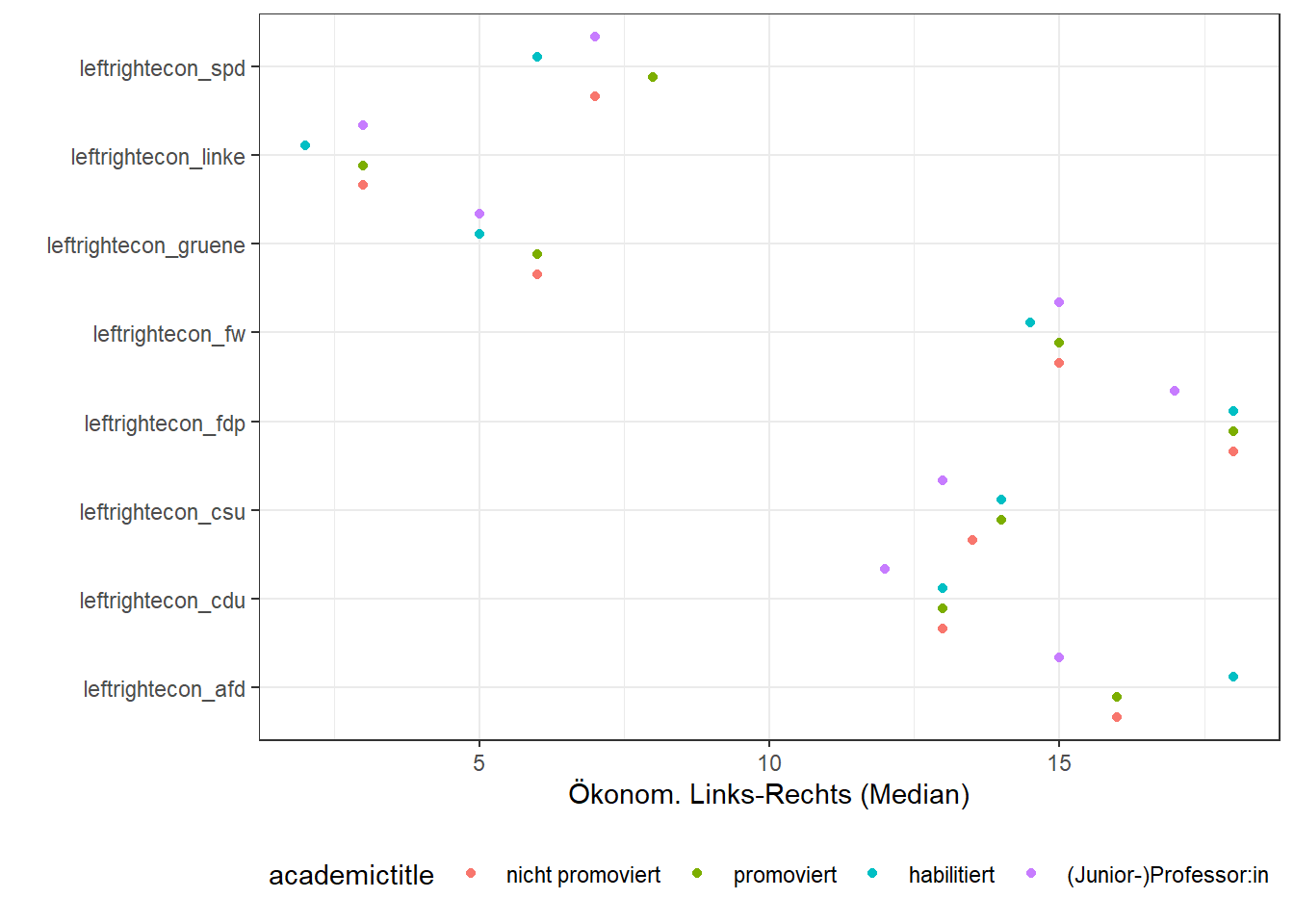
positions_tidy
Der Datensatz eignet sich u.a. um Positionen im Zeitverauf zu analysieren.
# Einlesen der Daten
positions_tidy <- readRDS("oes21_positions_tidy.rds")
# Entwicklung von Salienz und Position beim Liberalismus
positions_tidy %>%
filter(item == "liberalism") %>%
ggplot(aes(x = year,
y = mean,
color = party)) +
geom_point(shape = 1) +
geom_line() +
theme_bw() +
ylab("Liberalismus") +
xlab("Year") +
facet_wrap(~ scale) +
scale_color_manual(values = c("darkblue",
"black",
"steelblue",
"#F9ea4c",
"orange",
"darkgreen",
"pink",
"brown",
"red"))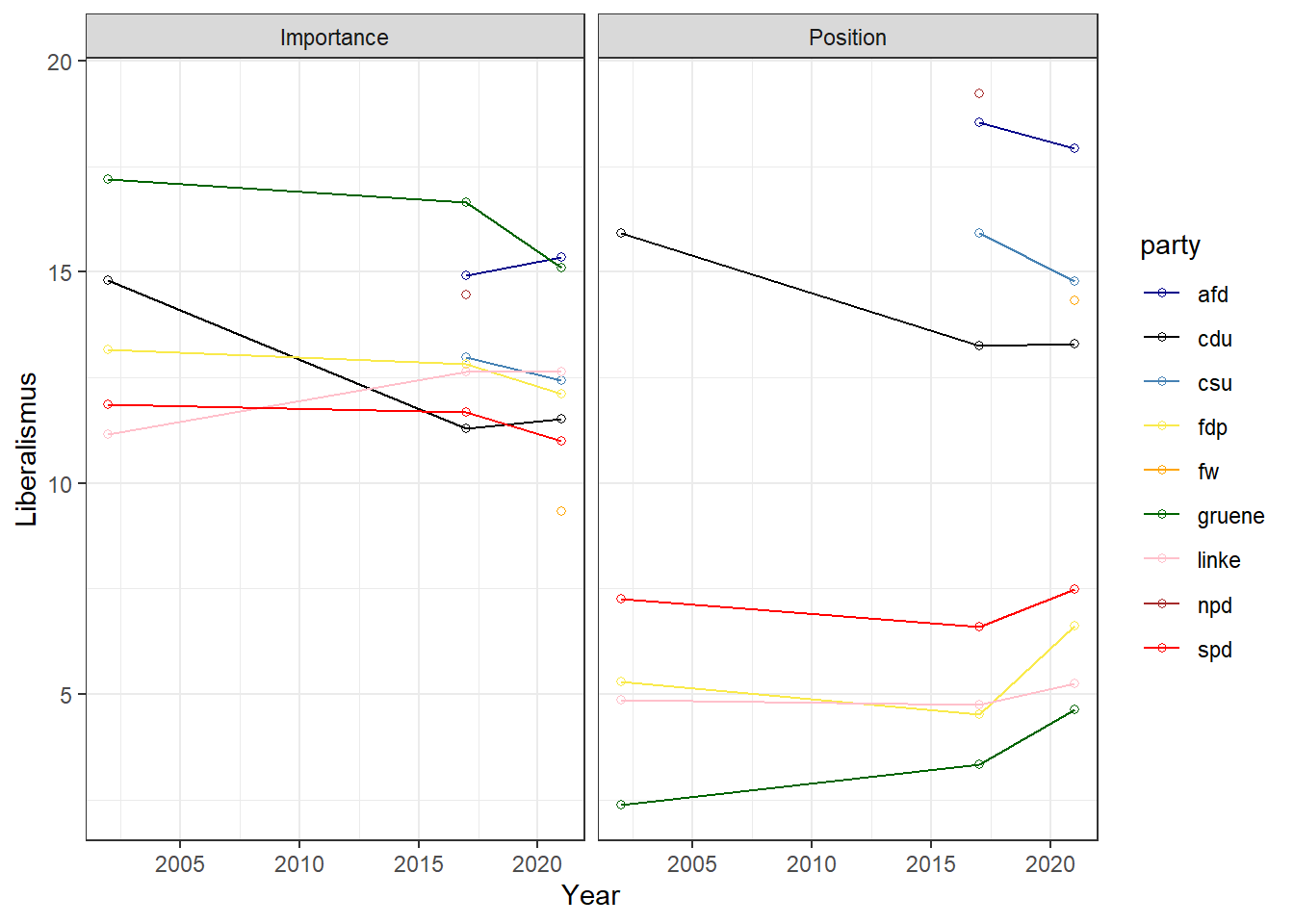
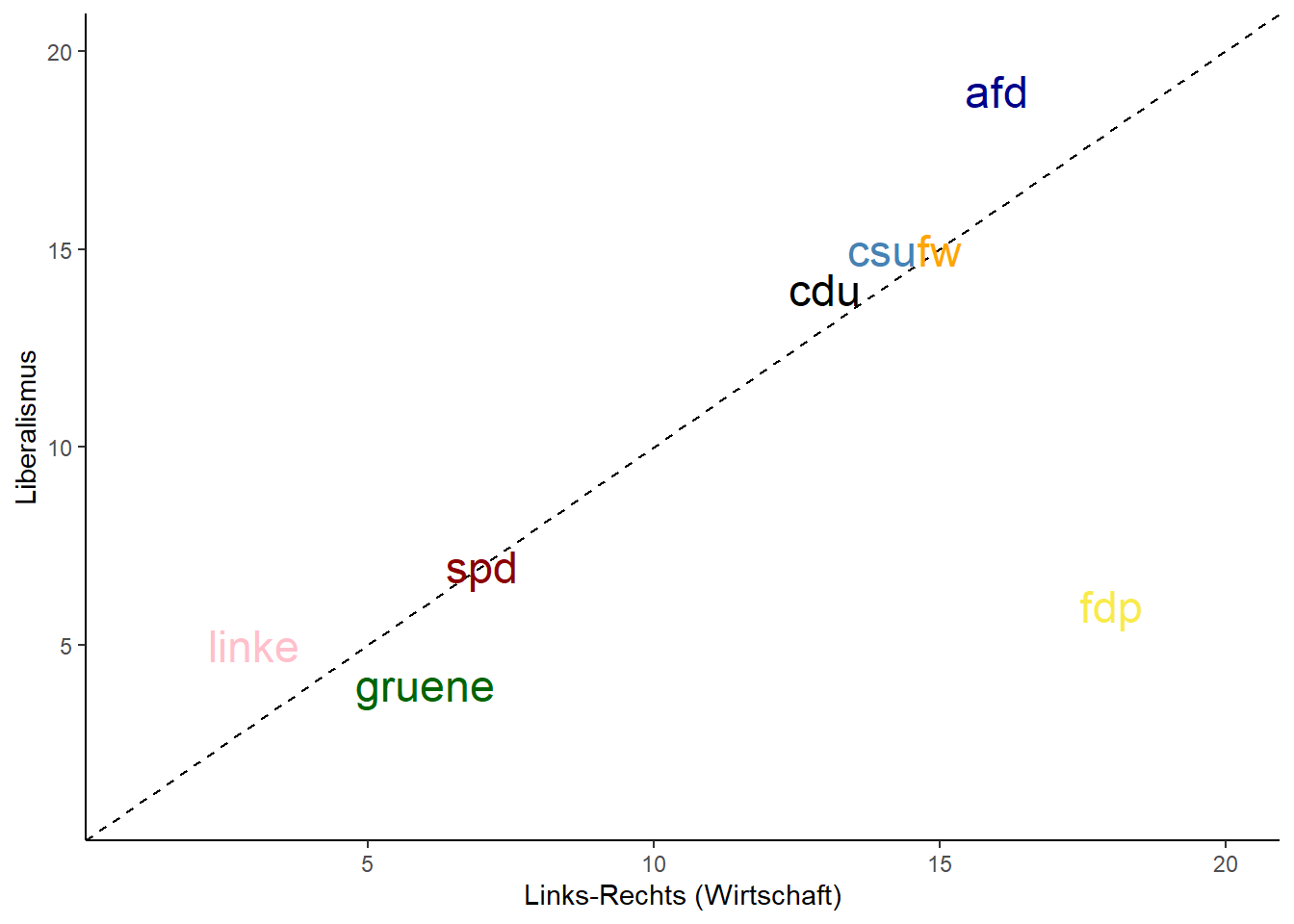
medians_wide / means_wide
Der Datensatz eignet sich um einfache Korrelationen der Positionen auf unterschiedlichen Dimensionsn vorzunehmen. Außerdem können die Daten einfach an bestehende Daten (bspw. CHES, CMP) gemerged werden.
# Einlesen der Daten
medians_wide <- readRDS("oes21_medians_wide.rds")
# 2D-Politikraum
medians_wide %>%
ggplot(aes(x = leftrightecon,
y = liberalism,
color = party)) +
geom_abline(slope = 1, intercept = 0, lty = 2) +
geom_text(aes(label = party), size = 6) +
geom_smooth(se = F) +
theme_classic() +
ylab("Liberalismus") +
xlab("Links-Rechts (Wirtschaft)") +
guides(color = F) +
scale_color_manual(values = c("darkblue",
"black",
"steelblue",
"#F9ea4c",
"orange",
"darkgreen",
"pink",
"darkred")) +
lims(x = c(1,20),
y = c(1,20))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'